Les deux modèles de gouvernance data les plus répandus
Les sources de données, auparavant centralisées, peuvent désormais provenir de sources diverses et de natures différentes (données de vente omnicanales, ERP, données externes, etc.). Le volume de données à traiter se multiplie sans cesse.
Ainsi le risque d’obtenir des informations non vérifiées et peu utiles augmente, surtout si aucune stratégie de gouvernance data n’a été mise en place.
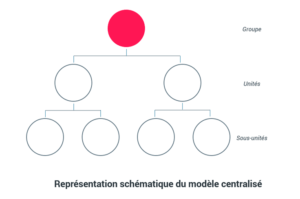
Modèle centralisé
En ce qui concerne le modèle centralisé, les données de référence du Système Informatique (SI) sont rassemblées en un seul endroit (majoritairement dans un MDM, Master Data Management). Le MDM joue un rôle central dans le système : il permet la mise en place de workflows de validation de données qui proviennent d’autres sources telles que des saisies manuelles ou des solutions automatisées.
Ce modèle est à adopter lorsque les données nécessitent fortement d’être validées et/ou supervisées.
Dans ce modèle, les structures informatiques sont centralisées, très souvent au niveau du siège social. La donnée collectée par l’ensemble du groupe, et ses filiales, est, elle aussi, remontée en central.
La gouvernance de données centrale s’illustre par un point de contrôle unique au niveau du groupe pour ce qui concerne les prises de décision. Les autres niveaux (filiales) possèdent très peu, voire pas du tout, de responsabilité et d’autonomie dans l’accès, le choix et l’analyse des données.
Le partage de la donnée est dans ce cas très limité. Par exemple, une filiale localisée en France n’aura pas accès aux données d’une filiale localisée au Royaume-Uni.
Au-delà de cela, c’est le groupe qui décide quelles données partager et avec qui. L’autonomie des métiers et filiales est très limitée.
Les + :
- Un contrôle systématique de la donnée
- Une définition et un catalogage des données plus homogène
- Une politique et une stratégie plus facilement déployable au niveau des métiers et filiales
Les – :
- Du fait d’une absence d’autonomie, pas d’incitation au niveau métier / filiale à produire de la donnée de qualité
- Risque de perdre les spécificités locales / métiers dans des reportings trop génériques
- Risque d’engorgement / lenteur du central à produire les états utiles au local
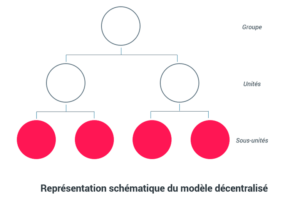
Modèle décentralisé
Contrairement au modèle précédent, le modèle décentralisé favorise la répartition – et le partage selon les cas – de la donnée.
Il n’est plus question de gouvernance de la donnée par le groupe uniquement. Les pays, les business units et les filiales agissent en totale autonomie tout en répondant à des normes communes.
Le modèle décentralisé prouve de plus en plus son efficacité et a tendance à se répandre. Un grand nombre d’entreprises internationales tendent à adopter ce mode de « décentralisation » de la donnée. Par ailleurs, il répond à la logique de l’Open data, la donnée accessible à tous.
La data collectée par chacun est accessible et utilisable par tous, dans le respect, bien entendu, des règles de confidentialité.
Les + :
- Un accès à la donnée rapide et adapté aux besoins de chacun, permettant une plus grande efficacité opérationnelle
- Autonomisés, les métiers / filiales sont incités à produire de la donnée de qualité pour en profiter directement
Les – :
- Risque de concurrence entre business units / filiales, utilisant la donnée des autres à des fins commerciales
- Plus grande difficulté à gérer le contrôle des données
- Risque de ne pas avoir de définition de la donnée homogène et de produire des états faux
Un modèle à mi-chemin : modèle dit fédéré
La plupart des entreprises centralisées, prenant le chemin de la décentralisation, se retrouvent dans ce modèle. L’organisation et la culture historiques prennent encore du temps à changer et à s’adapter.
L’idée est fondée sur une gouvernance partagée des données. Les responsabilités sont donc elles aussi réparties sur l’ensemble des niveaux existant dans l’entreprise.