Scient s’est rendu à la 10e Edition de Devoxx France ! Nous vous proposons dans cet article un retour d’expérience sur les sujets qui nous ont marqués et ce que nous allons en retenir.

Scient s’est rendu à la 10e Edition de Devoxx France ! Nous vous proposons dans cet article un retour d’expérience sur les sujets qui nous ont marqués et ce que nous allons en retenir.

Le “12 Factor app” est un manifeste proposant 12 bonnes pratiques concernant le développement d’applications Cloud.

Si l’on s’en réfère à la définition donnée par Gartner, la CDP “est une technologie marketing qui permet d’unifier les données clients en provenance du marketing et de tous les autres canaux afin de construire des profils clients et d’optimiser le timing et le ciblage des messages et des offres ».
Il s’agit donc d’une plateforme qui permet :
– De réunir la donnée client en provenance de différentes sources (web, mobile, CRM, social media, e-commerce etc.)

Avec la crise sanitaire et les bouleversements qu’elle a impliqués, la tendance à la rationalisation des coûts IT s’est d’autant renforcée. Les entreprises se sont empressées de prendre des mesures, comme réduire les effectifs ou exploiter au maximum leurs actifs IT....

De la microélectronique aux infrastructures de télécommunications, les TIC voient leur place déjà importante s’accroître davantage. C’est le domaine de nombreux challenges qui font évoluer nos sociétés actuelles vers des futurs plus innovants et connectés. Ces vingt...

La data est une ressource de plus en plus maîtrisée et exploitée par les entreprises.
Le cloisonnement de la donnée tend à disparaître chez les organisations. Gouverner et structurer la data devient donc nécessaire à toute entreprise voulant s’adapter et se développer dans les meilleures conditions.
L’organisation de l’entreprise autour de la donnée dépend d’une multitude de variables, avec notamment :
Entre culture, organisation et stratégie, les entreprises ont le choix entre différents modèles de gouvernance. Du plus centralisé au décentralisé, quels sont les avantages et inconvénients de chacun d’entre eux ?
Pour rédiger cet article, nous nous sommes basés sur les retours d’expérience de nos clients.
Les sources de données, auparavant centralisées, peuvent désormais provenir de sources diverses et de natures différentes (données de vente omnicanales, ERP, données externes, etc.). Le volume de données à traiter se multiplie sans cesse.
Ainsi le risque d’obtenir des informations non vérifiées et peu utiles augmente, surtout si aucune stratégie de gouvernance data n’a été mise en place.
En ce qui concerne le modèle centralisé, les données de référence du Système Informatique (SI) sont rassemblées en un seul endroit (majoritairement dans un MDM, Master Data Management). Le MDM joue un rôle central dans le système : il permet la mise en place de workflows de validation de données qui proviennent d’autres sources telles que des saisies manuelles ou des solutions automatisées.
Ce modèle est à adopter lorsque les données nécessitent fortement d’être validées et/ou supervisées.
Dans ce modèle, les structures informatiques sont centralisées, très souvent au niveau du siège social. La donnée collectée par l’ensemble du groupe, et ses filiales, est, elle aussi, remontée en central.
La gouvernance de données centrale s’illustre par un point de contrôle unique au niveau du groupe pour ce qui concerne les prises de décision. Les autres niveaux (filiales) possèdent très peu, voire pas du tout, de responsabilité et d’autonomie dans l’accès, le choix et l’analyse des données.
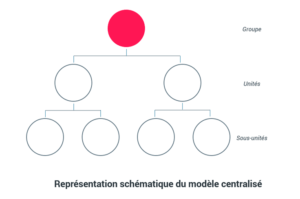
Le partage de la donnée est dans ce cas très limité. Par exemple, une filiale localisée en France n’aura pas accès aux données d’une filiale localisée au Royaume-Uni.
Au-delà de cela, c’est le groupe qui décide quelles données partager et avec qui. L’autonomie des métiers et filiales est très limitée.
Les + :
Les – :
Contrairement au modèle précédent, le modèle décentralisé favorise la répartition – et le partage selon les cas – de la donnée.
Il n’est plus question de gouvernance de la donnée par le groupe uniquement. Les pays, les business units et les filiales agissent en totale autonomie tout en répondant à des normes communes.
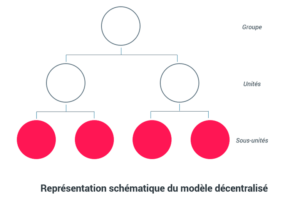
Le modèle décentralisé prouve de plus en plus son efficacité et a tendance à se répandre. Un grand nombre d’entreprises internationales tendent à adopter ce mode de « décentralisation » de la donnée. Par ailleurs, il répond à la logique de l’Open data, la donnée accessible à tous.
La data collectée par chacun est accessible et utilisable par tous, dans le respect, bien entendu, des règles de confidentialité.
Les + :
Les – :
La plupart des entreprises centralisées, prenant le chemin de la décentralisation, se retrouvent dans ce modèle. L’organisation et la culture historiques prennent encore du temps à changer et à s’adapter.
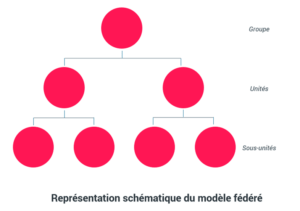
L’idée est fondée sur une gouvernance partagée des données. Les responsabilités sont donc elles aussi réparties sur l’ensemble des niveaux existant dans l’entreprise.
La crise sanitaire a gravement touché un grand nombre d’entreprises. L’évidence mise en lumière par la situation est la suivante : certaines entreprises ne fonctionnent et ne perdurent que si et seulement si elles restent ouvertes. Or, entre confinements successifs, restrictions et nouvelles réglementations, une grande majorité s’est retrouvée fortement secouée par la crise.
Le back-to-work a été très différent en fonction des pays, des équipes, etc. Il est devenu très compliqué d’obtenir les infos dans d’autres pays, comme connaître les secteurs ouverts ou fermés. Selon certaines entreprises, s’il n’y avait pas eu de relai au niveau local pour la data, cela aurait été très compliqué pour les groupes d’obtenir des informations essentielles.
Il s’agit donc d’une période où plusieurs questions se posent sur la gouvernance et le partage de l’information et de la data notamment avec les filiales.
Parallèlement, on assiste à une ouverture à la data. La donnée gagne de plus en plus d’importance et de légitimité aux yeux d’un nombre croissant d’entreprises et de personnes. L’Open data, sujet qui illustre bien la situation, est une thématique d’actualité qui continue de faire débat.
Conceptualiser les modèles de gouvernance data est un vrai défi quand il s’agit de prendre en compte les zones géographiques.
Effectivement, chaque région ou pays possède sa propre réglementation concernant la donnée. En ce qui concerne l’Europe, cela reste plutôt simple d’élaborer un modèle de gouvernance data adapté aux besoins de l’entreprise.
La complexité réside dans le partage de la donnée entre différentes régions dont les réglementations varient et/ou divergent.
En ce qui concerne les données aux Etats-Unis, en Chine (data privacy Chine) et en Russie, il existe une certaine particularité. Dans ces trois zones, la collecte, le stockage et le partage de la data sont régies par des réglementations spécifiques. Il est ainsi très difficile d’exporter la data de Chine. Par exemple, certaines entreprises internationales opérant aux Etats-Unis se chargent de partager la donnée avec leurs partenaires préférentiels.
Mettre en place un modèle de gouvernance data, quel qu’il soit, passe d’abord par une redéfinition des termes et des objectifs communs. La communication au sein de l’entreprise est impérative. Pour que le modèle soit bien appliqué et fonctionne bien, il faut d’abord pouvoir le mettre en place. Et pour cela, avoir le même vocabulaire est essentiel. Revoir les définitions communes permet d’améliorer et faciliter la communication, et ainsi l’efficacité du modèle.
Cela représente souvent un chantier considérable : aligner tout le monde sur des définitions communes en tenant compte des spécificités n’est pas évident. Cependant, cela définit un socle commun. De cette manière, le partage des KPIs au sein de l’entreprise est facilité. De plus, avoir une base homogène permet à la DG d’avoir une vision globale de l’entreprise.
Il n’existe pas de modèle parfait. Chacun possède ses avantages et inconvénients. Le choix de l’entreprise dépend de nombreuses variables. Pour faire le meilleur choix possible, les dirigeants doivent avoir une vision d’ensemble sur les données, mais avant tout sur leur culture et leurs objectifs.